Kafka คือ Message Queue ที่คอยเชื่อมต่อระหว่าง Producer(ผู้ผลิต) และ Consumer(ผู้บริโภค) โดย Producer จะเป็นตัวผลิต Message ไปส่ง Message Queue ซึ่งจะรอให้ Consumer หยิบแต่ละ Message ไปใช้งาน นอกจากนั้น Kafka ยังเป็นตัว Distributed System ได้อีกด้วยคือเราสามารถสร้าง Producer หลายๆตัวขึ้นมาได้เพื่อให้สามารถรองรับการทำงานกับระบบที่มี Transaction มากๆ
เพื่อความเข้าใจง่ายจะขอยกตัวอย่างกับร้านอาหาร ตอนเริ่มต้นเราเปิดร้านอาหารลูกค้าก็ยังไม่มากเพราะยังไม่ค่อยมีใครรู้จักร้านเรา เราจ้างเด็กเสิร์ฟคนเดียวก็พอ แต่เมื่อเวลาผ่านไปร้านอาหารเราดังขึ้นมาติดมิชลินสตาร์คนเข้ามาอย่างล้นหลามการมีเด็กเสิร์ฟคนเดียวก็คงน้อยไปเพราะลูกค้าจะรอนานมากหรือคงจะไม่เข้าร้านเราอีกเลย ดังนั้นเราจึงแก้ปัญหาโดยการจ้างเด็กเสิร์ฟเพื่อให้สามารถให้บริการลูกค้าได้อย่างรวดเร็ว ซึ่งเด็กเสิร์ฟที่เพิ่มขึ้นนั้นก็เปรียบได้กับ Kafka ที่สามารถสร้างหลายๆ Producer เพื่อให้การทำงานรวดเร็วขึ้น
 |
| Kafka Architecture |
Producer
เป็นตัวที่คอย Push Message ไปยัง Broker เมื่อพร้อมใช้งาน Producer จะเป็นตัวที่ส่ง Message ไปยัง Broker เพียงอย่างเดียวโดยไม่ต้องการ Response ตอบกลับจาก Broker
Consumer
Consumer
Consumer ตัวที่หยิบเฉพาะ Message ที่แต่ละตัวสนใจไปใช้งานโดยอ่านข้อมูลแบบ Offset(อ่านค่าจากข้อมูลที่เก่าที่สุดหรือข้อมูลที่มาก่อน) จาก Partition ของ Broker แต่ก่อนนั้นเราจะพบปัญหาว่าเรามี Producer แต่ Consumer นั้นมีจำกัด เช่น ร้านอาหารมีกุ๊กทำอาหารหลายคนแต่เด็กเสิร์ฟมีคนเดียวก็ทำให้ลูกค้ารอนานและถ้าวันไหนเด็กเสิร์ฟป่วยร้านอาหารก็ต้องปิดเลยทีเดียว กุ๊กก็เปรียบเหมือน Producer เด็กเสิร์ฟก็เปรียบเหมือน Consumer ในกรณีนี้เราสามารถเพิ่ม Consumer ขึ้นมาได้ เราจะเรียกว่าเป็น Consumer Group เพื่อรองรับการทำให้มันรวดเร็วและทำงานแบบ Parallel กันไปได้
Kafka สามารถทำงานแบบ Event-Driven หรือสามารถทำงานแบบ Parallel ได้ สมมติมี Event เกิดต้อง Process 3 Message ตัว Event-Driven นี้เองสามารถ Process 3 Message พร้อมกันได้เลยไม่ต้อง Process ทีละ Message เหมือน Tools ตัวอื่นๆ ตัวอย่างเช่นการสร้างเว็บไซต์ ปกติแล้ว Event ที่เกิดขึ้นคือจะมีลักษณะเป็น API หลายๆเส้นที่ต้อง Call และรอผล Call จาก API เส้นแรกไปจนถึงเส้นสุดท้ายแล้วนำมาประกอบกันเพื่อแสดงผลบนหน้าเว็บ แต่ลักษณะของ Event-Driven นั้นไม่จำเป็นต้องมีลำดับ การทำงานจะเป็นลักษณะการ Call ไปครั้งเดียวและรอผลใน Event ที่สนใจแล้วแสดงผลทีเดียว
Broker
ภายใน Kafka จะประกอบไปด้วยหลายๆ Broker รวมกันเป็น Cluster ทำหน้าที่จัดการในกรณีที่ระบบมี Message จำนวนมากๆเพื่อกระจาย Load ไปยังเครื่องต่างๆ(Load Balance) แต่ละ Broker จะทำหน้าที่เก็บ Event ที่เกิดขึ้น และยังสามารถออกแบบให้เก็บข้อมูลที่ซ้ำกันได้ เช่น Broker1 เก็บข้อมูลชุด A ซึ่ง Broker2 เองก็สามารถเป็นเก็บข้อมูลชุด A ได้เช่นกัน การทำงานเช่นนี้เพื่อป้องกันข้อมูลจาก Broker ใด Broker หนึ่งเสียหาย ซึ่งหากเกิดความเสียหายเราสามารถกู้ข้อมูลจาก Broker อื่นขึ้นมาได้
Topics
เป็นการจัดกลุ่มข้อมูลภายใน Kafka Cluster เมื่อ Producer Push Message ลงไป โดยชื่อของแต่ละ Topic นั้นไม่ควรซ้ำกัน(Unique) เพื่อใช้ในการแยกชุดของข้อมูล ภายในแต่ละ Topic จะมีการแบ่งข้อมูลเป็นกลุ่มๆอีกเรียกว่า Partition
Partition
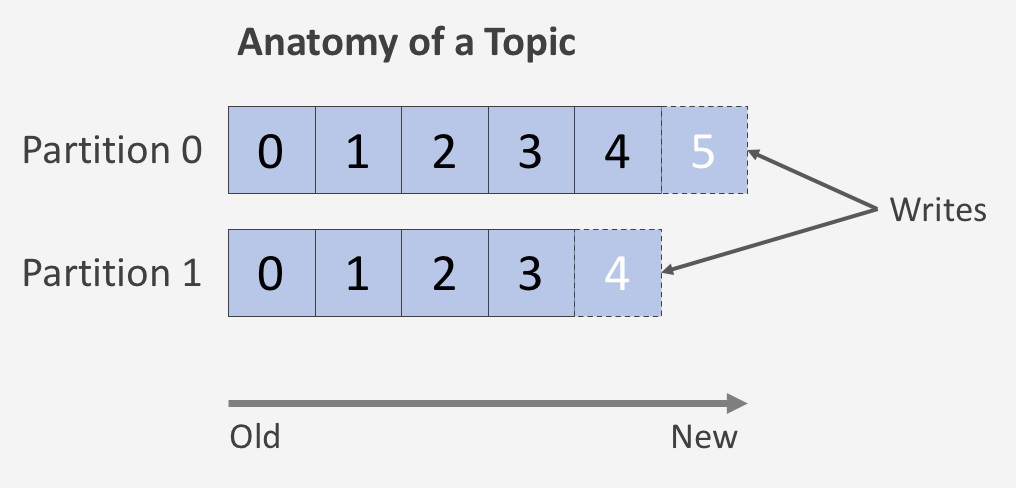
Partition ถูกสร้างขึ้นมาเพื่อใช้ในการเก็บและกระจายข้อมูลที่รับเข้ามา(Distributed System) เพื่อป้องกันไม่ให้เครื่องใดเครื่องหนึ่งรับ Load ที่มากเกินไป อย่างไรก็ตามต้องมีการคำนวณ Partition ที่เพิ่มขึ้นมาให้เหมาะสมเพราะยิ่ง Partition มากจะทำให้เกิด delay time มากขึ้นตามเช่นกัน
การจัดเรียงข้อมูลใน Partition นั้นจะเริ่มจากเลข 0,1,2,3,4,5... ไปเรื่อยๆซึ่งจะเรียกเลขชุดนี้ว่าเป็น Offset หากมีการเขียนข้อมูลลงไปใหม่ ข้อมูลจะถูกเขียนไว้ด้านท้ายสุดหรือข้อมูลที่เก่าจะอยู่ด้านหน้า ข้อมูลที่ใหม่สุดจะอยู่ด้านหลังนั่นเอง
Zookeeper
Zookeeper เป็นตัวที่สำคัญมากเพราะทำหน้าที่เป็นตัวจัดการและควบคุม Broker ทุกตัวใน Cluster เช่นหากแต่ละ Broker ต้องการทำงานร่วมกันจะอาศัย Zookeeper เป็นตัวติดต่อสื่อสาร เป็นตัวคอยแจ้งเตือนสถานะของ Broker แต่ละตัวว่า Fail หรือไม่ หาก Zookeeper ล้มเหลวก็จะส่งผลเสียร้ายแรงต่อระบบ
การใช้งานของ Kafka
- Messaging เป็นการรับส่งข้อมูลภายในระบบ เช่น หากเราต้องการส่งข้อความ ข้อความจะถูกสร้างโดย Producer ส่งไปยัง Kafka Server จากนั้น Consumer ไหนสนใจข้อความไหนก็หยิบเฉพาะที่สนใจนำไปใช้งาน
- Stream Processing เหมาะสำหรับระบบที่ทำงานแบบ Real-Time เพราะ Kafka เป็นระบบที่สามารถจัดการข้อมูลได้อย่างรวดเร็ว
- Log คือการเก็บรายละเอียดต่างๆที่เกิดขึ้นจากผู้ใช้งานเพื่อให้สามารถเก็บเหตุการณ์ต่างๆที่เกิดขึ้นบนระบบได้ โดยทั่วไปแล้วมักจะเก็บ Log สำหรับเหตุการณ์ที่มีการเปลี่ยนแปลงของข้อมูลหรือการ Add, Edit และ Delete การ Store
- Website Activity Tracking จะนำไปใช้กับ Web Application เช่น เราเปิดดูหนังผ่านเว็บหนึ่งแล้วปิดไป เมื่อเปิดอีกรอบระบบสามารถจำได้ว่าเราเปิดดูเรื่องอะไรนาทีที่เท่าไหร่
- De-coupling System Dependencies ปกติแล้ว Message ต่างๆจะถูกส่งผ่านยัง Kafka Queue ซึ่งการทำงานของ Queue กับ Database นั้นจะแยกกันทำงาน ทำให้ Kafka สามารถช่วยให้ลด Load ของ Database ได้มาก